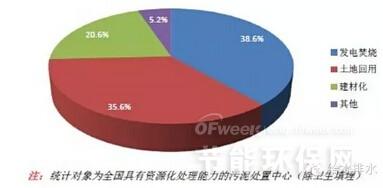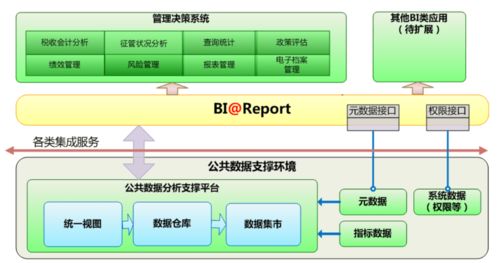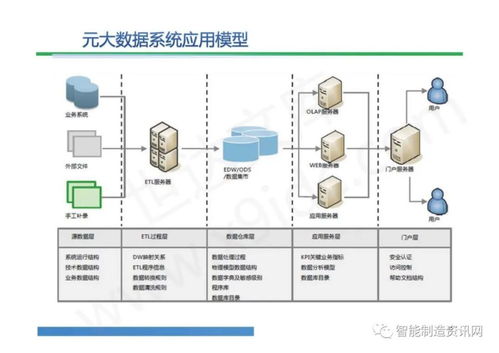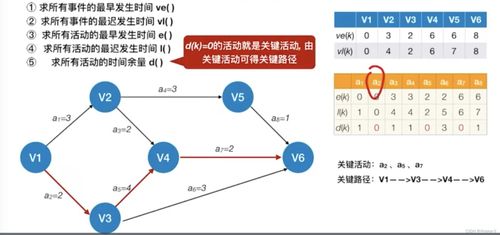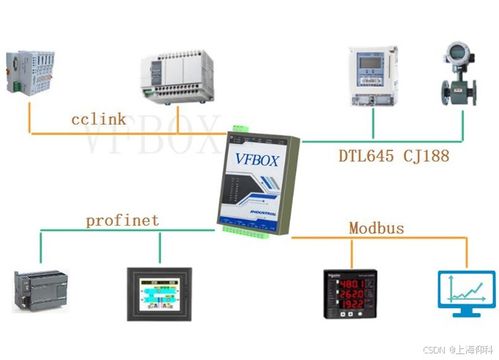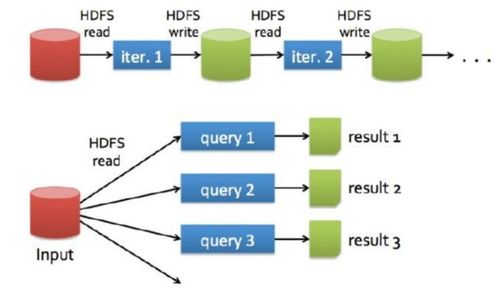
Apache Spark作為一種快速、通用的大規模數據處理引擎,廣泛應用于數據分析與機器學習領域。下面從分區、系統架構、算子和任務提交方式四個方面詳細介紹Spark技術棧的核心概念。
一、分區(Partitioning)
Spark的數據處理基于分布式數據集(RDD、DataFrame等),分區是數據劃分的基本單位。每個分區是數據的一個子集,可以并行處理。分區策略包括:
1. 默認分區:根據數據源和集群配置自動劃分。
2. 自定義分區:通過repartition()或coalesce()調整分區數量,或使用partitionBy()按鍵分區,優化數據本地性和負載均衡。
合理分區能顯著提升并行效率,避免數據傾斜。
二、系統架構(System Architecture)
Spark采用主從架構,核心組件包括:
1. Driver:運行用戶程序的JVM進程,負責解析代碼、生成執行計劃并調度任務。
2. Cluster Manager:資源管理器(如Standalone、YARN、Mesos),分配集群資源。
3. Executor:在工作節點上運行的進程,執行具體任務并緩存數據。
執行流程:Driver將作業拆分為任務,通過Cluster Manager分配給Executor并行執行。
三、算子(Operators)
Spark算子分為轉換(Transformation)和行動(Action)兩類:
1. 轉換算子:惰性執行,生成新RDD/DataFrame,如map()、filter()、groupBy()。
2. 行動算子:觸發實際計算并返回結果,如count()、collect()、saveAsTextFile()。
算子優化(如謂詞下推、廣播連接)能減少Shuffle操作,提升性能。
四、任務提交方式(Job Submission)
Spark支持多種任務提交模式:
- 本地模式:通過
local[*]在單機模擬分布式環境,適用于測試。 - 集群模式:
- Standalone:使用Spark內置資源管理器。
- YARN/Mesos:與Hadoop或其他集群框架集成。
提交命令示例:spark-submit --master yarn --deploy-mode cluster app.jar。
五、數據處理流程
典型數據處理步驟:
1. 讀取數據源(如HDFS、Kafka)創建RDD/DataFrame。
2. 應用轉換算子進行過濾、聚合等操作。
3. 通過行動算子輸出結果或保存至存儲系統。
Spark的內存計算和DAG調度器確保高效執行,適用于批處理、流處理和迭代計算。
掌握分區策略、架構原理、算子特性及提交方式,是構建高效Spark應用的關鍵。結合實際數據特征調整配置,可充分發揮其分布式計算優勢。