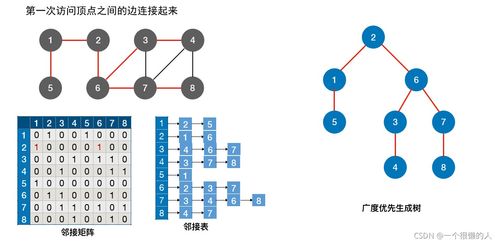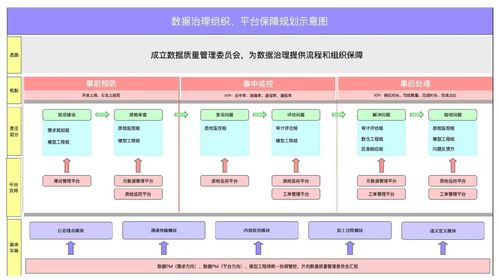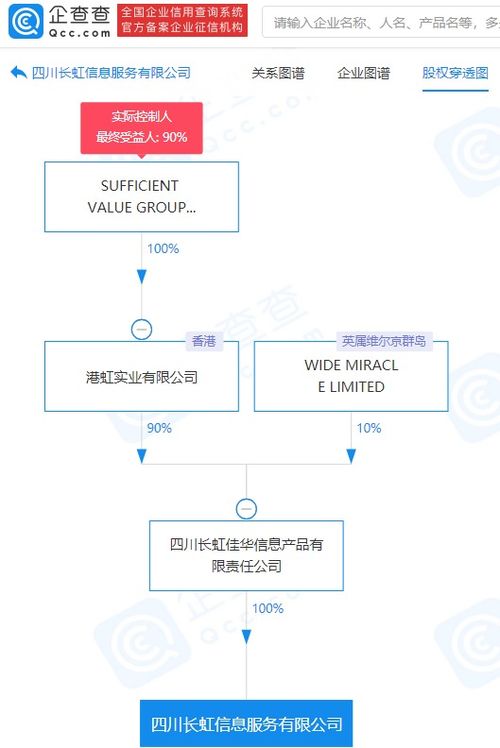
數據處理是當今信息時代的核心環節,涉及從原始數據中提取有價值信息的過程。隨著大數據、人工智能和物聯網技術的快速發展,高效的數據處理方法變得尤為重要。
數據處理的基本流程
數據處理通常包含四個關鍵步驟:
- 數據收集:從各種來源獲取原始數據,包括數據庫、傳感器、社交媒體等
- 數據清洗:處理缺失值、異常值和重復數據,確保數據質量
- 數據轉換:將數據轉換為適合分析的格式,包括規范化、聚合和特征工程
- 數據存儲:將處理后的數據存儲在適當的數據倉庫或數據湖中
現代數據處理技術
批處理與流處理
傳統批處理適合處理大量歷史數據,而流處理技術如Apache Kafka和Apache Flink能夠實時處理數據流,滿足現代企業對實時洞察的需求。
云計算與分布式計算
云平臺如AWS、Azure和Google Cloud提供了可擴展的數據處理服務,而分布式計算框架如Apache Spark大幅提升了海量數據處理效率。
數據湖與數據倉庫
數據湖存儲原始格式的所有數據,而數據倉庫存儲經過處理的結構化數據,兩者結合形成了現代數據架構的基礎。
數據處理的最佳實踐
- 建立數據治理框架:確保數據質量、安全性和合規性
- 采用自動化流程:減少人工干預,提高處理效率和準確性
- 實施監控機制:實時跟蹤數據處理過程,及時發現和解決問題
- 注重數據安全:在數據處理全周期實施適當的安全措施
未來趨勢
人工智能和機器學習正深度融入數據處理流程,自動化數據清洗、智能特征工程和預測性分析將成為標準配置。邊緣計算的發展將使數據處理更接近數據源,減少延遲并提高效率。
數據處理不僅是技術挑戰,更是業務轉型的關鍵驅動力。組織需要持續優化數據處理能力,才能在數據驅動的競爭環境中保持優勢。