在當今大數據時代,如何從海量數據流或靜態數據集中快速、準確地找出出現頻率最高的前K個項(Top K Frequent Items),是搜索引擎、推薦系統、廣告投放、網絡監控、實時分析等眾多領域的核心需求。這一經典問題不僅考驗著算法的效率,更對底層的存儲支持服務提出了嚴峻的挑戰。本文將探討該問題的核心難點,并分析支撐其高效實現的存儲與服務架構。
一、問題定義與核心挑戰
問題定義:給定一個規模巨大的數據集(例如,數十億的搜索查詢詞、用戶點擊記錄、社交網絡標簽或日志條目),我們需要找出其中出現頻率(或計數)排名前K的元素。
核心挑戰:
1. 數據規模巨大(海量性):數據無法一次性裝入單機內存進行處理。
2. 數據動態變化(流式性):在很多場景下,數據以高速流的形式持續到達(如Twitter推文流),需要實時或近實時地更新統計結果。
3. 查詢響應要求高(實時性):系統需要能快速響應針對當前統計結果的查詢請求。
4. 精確與近似的權衡:在資源受限的情況下,有時可以接受近似結果以換取性能的巨大提升。
二、算法策略概覽
算法的選擇直接決定了處理效率,通常需要結合存儲服務進行設計。
- 基于外部排序與歸并的方法:適用于靜態數據集。將海量數據分片排序,然后多路歸并統計頻次,最后找出Top K。這高度依賴存儲系統高效的分片I/O能力。
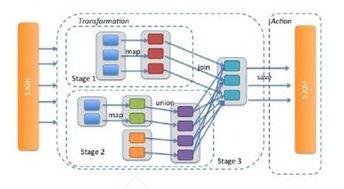
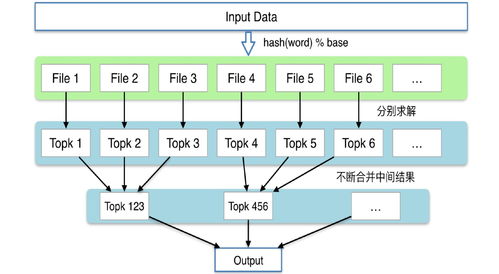
- 哈希分治與MapReduce范式:經典的海量數據處理方法。通過哈希將數據分散到多個節點(分治),每個節點計算局部頻次,最后匯總產生全局Top K。這需要分布式存儲(如HDFS)和計算框架(如Hadoop/Spark)的支持。
- 基于堆(Heap)的在線算法:維護一個大小為K的最小堆,用于跟蹤當前遇到的高頻項。通常需要結合其他數據結構(如哈希表)來快速更新計數。此方法對內存友好,但精確處理海量數據時仍需與外部存儲結合。
- 近似算法:Count-Min Sketch與Lossy Counting:為了應對數據流和內存限制,常用概率數據結構。例如,Count-Min Sketch使用多個哈希函數在固定大小的二維計數陣列中累加數據,以可控的誤差概率估計頻次。這類算法能極大節省內存和計算資源,其狀態(即Sketch矩陣)的持久化和快速訪問對存儲服務提出了特定需求。
三、存儲支持服務的關鍵角色
高效解決Top K問題離不開強大的底層存儲服務,其設計需考慮以下方面:
- 數據攝入層(Ingestion):
- 對于流數據,需要高吞吐、低延遲的消息隊列服務(如Apache Kafka, Pulsar)來緩沖和分發數據流,供后續處理節點消費。
- 存儲服務需支持高速的批量寫入和追加操作。
- 中間狀態存儲:
- 在分布式處理中,各節點的局部統計結果(如哈希表、Sketch、部分排序結果)需要可靠的存儲,以備匯總階段讀取。這要求存儲服務具備高可用性和一致性(根據需求選擇CP或AP)。
- 鍵值存儲(如Redis, RocksDB, Cassandra)常用于存儲鍵(數據項)和值(當前計數或Sketch狀態)。Redis等內存數據庫可提供極快的更新速度,適合高頻更新的實時場景;而RocksDB等嵌入式存儲引擎則提供了更經濟的持久化能力。
- 持久化與查詢服務:
- 最終的Top K結果或用于快速查詢的完整頻次索引需要被持久化。關系型數據庫、文檔數據庫或專用的時序數據庫/OLAP系統(如ClickHouse, Druid)可以勝任此角色,它們支持對預計算結果的快速聚合查詢。
- 存儲系統需要提供高效的隨機讀和范圍查詢能力,以支持對Top K列表的快速檢索和更新。
- 架構示例:Lambda/Kappa架構的體現
- 批處理層:利用HDFS/S3存儲全部原始數據或歷史批次數據,使用Spark等框架進行全量計算,生成準確但延遲較高的Top K結果。
- 速度層/流處理層:使用Kafka作為數據源,由Flink, Storm等流處理引擎消費,在內存中維護近似結構(如Sketch)或增量更新結果,并將實時Top K視圖寫入低延遲存儲(如Redis)供查詢。
- 服務層:負責合并批處理結果與實時結果,或直接提供查詢接口。這要求底層存儲服務能夠支持高并發的點查詢和可能的數據合并操作。
四、技術選型與實踐考量
在實踐中,構建系統時需綜合考量:
- 數據特性:是靜態的還是流式的?數據分布的傾斜程度如何?
- 精度要求:必須100%準確,還是可以接受微小誤差?
- 延遲要求:秒級、分鐘級還是小時級更新?
- 資源預算:內存、CPU、存儲成本的限制。
- 存儲服務選型:根據一致性、持久化、延遲和吞吐需求選擇組合,例如“Kafka + Flink + Redis + ClickHouse”是一種常見的組合,分別承擔流緩沖、實時計算、實時狀態存儲和批量結果持久化與查詢的角色。
###
海量數據下的最高頻K項問題,是一個算法與系統工程緊密結合的典范。任何高效的算法都離不開為其量身定制的存儲支持服務。從高速攝入、分布式中間狀態管理到最終結果的持久化與快速服務,每一層存儲組件的選擇和設計都直接影響著整個系統的性能、準確性和擴展性。理解并優化這條從數據到洞察的完整鏈路,是應對大數據挑戰的關鍵。